Petiano: Vitor Rodrigues da Cunha Estima (lattes)
Orientador: Prof. Dr. Luciano Antonio Digiampietri (lattes)
Atualmente, diversas informações relacionadas a redes sociais estão disponíveis de maneira digital, permitindo o desenvolvimento de diferentes soluções para analisar, entender ou otimizar tarefas que possam utilizar dessas informações. Exemplos dessas tarefas são a recomendação personalizada de conteúdo, a identificação de especialistas em um dado assunto, identificação antecipada de epidemias e a predição de relacionamentos.
A predição de relacionamentos (link prediction) visa a identificar (ou sugerir) potenciais relacionamentos entre dois indivíduos de uma rede social. Este problema pode ser visto sob diferentes perspectivas. Uma delas é a identificação de links (ou relacionamentos) faltantes, isto é, a identificação de relacionamentos que não estão presentes em uma dada rede (por exemplo, uma rede online de amizades), porém que existem no mundo real. De maneira ortogonal, observando-se apenas informações de uma dada rede social, é possível predizer a ocorrência futura de relacionamentos (analisados, tipicamente, dentro de uma janela de tempo). Este problema pode ser visto de maneira geral, tentando-se prever todos os relacionamentos que ocorrerão em uma janela de tempo futura (incluindo a reincidência de relacionamentos que ocorreram no passado) ou de maneira mais específica, tentando prever apenas relacionamentos inéditos (relacionamentos entre indivíduos que nunca se relacionaram no passado).
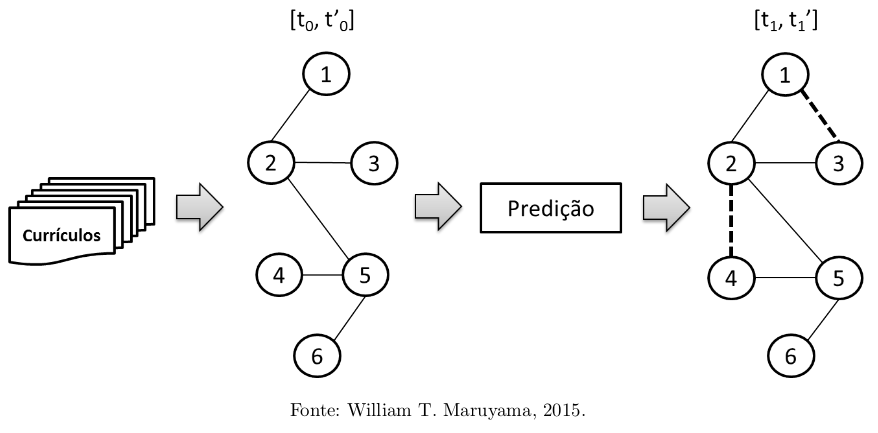
Existem diversas formas de abordar a tarefa de predição de relacionamentos, uma delas é tratar a questão como um problema de classificação binária em inteligência artificial, o qual classifica cada par de indivíduos como “irão se relacionar” ou “não irão se relacionar”. Apesar de apresentar resultados satisfatórios no contexto de predição de relacionamentos, esta abordagem sofre do desbalanceamento dos dados. Isto é, em uma rede social típica haverá muitos pares de pessoas que não se relacionarão e apenas uma pequena quantidade que irá se relacionar. Esse desbalanceamento é negativo já que, em certa frequência, faz com que os exemplos da classe minoritária sejam classificados incorretamente. Há diferentes abordagens para tratar essa questão e, neste trabalho, serão testadas e avaliadas diversas formas de filtragem horizontal de dados objetivando melhorar o desempenho da classificação.