
As máquinas são ótimas em trabalhar com padrões. Todos os tratamentos ficam mais fáceis quando os dados estão organizados ou, pelo menos, quando tem uma regra que rege a organização dos dados. Entretanto, como dito nessa matéria do Towards Data Science, a comunicação humana não é dada de forma estruturada e nem falamos em binário. Nós pensamos a respeito do mundo a nossa volta, nós sonhamos e tomamos decisões através de palavras, que podem ser traduzidas em dados desorganizados e bagunçados.
Levi Fernandes e Vitor Estima
O Processamento de Linguagem Natural (PLN; em inglês, Natural Language Processing) é a área de estudo da Ciência da Computação responsável por estudar as capacidades e limitações das máquinas em entender a linguagem dos seres humanos. Esse campo de pesquisa une as áreas de Computação e Linguística a fim de, através do estudo de como o cérebro humano funciona, conseguir aproximar os computadores da nossa linguagem, tida como natural.
O principal objetivo do PLN é fazer com que a máquina seja capaz de ler, decifrar, entender e fazer com que as linguagens humanas tenham sentido de uma maneira que seja valiosa.
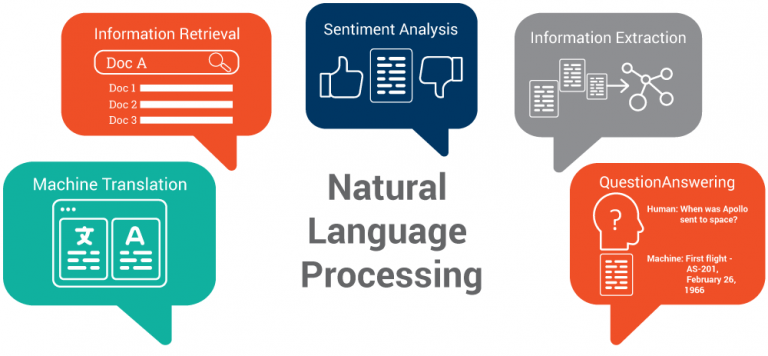
Durante uma palestra de Introdução a PLN na Cambrigde Data Science Bootcamp, foi acrescentado, porém, que as máquinas já possuem capacidades que achávamos serem reservadas apenas a nós humanos, como a de escrever e a de falar.
Algumas demonstrações da realidade dessas competências são: a fala pode ser vista durante as traduções pois o computador pode pronunciar fonemas de línguas diferentes, a escrita pode ser identificada durante a nossa digitação no teclado de um smartphone em que sempre há uma sugestão que prevê quais serão as próximas palavras, e o entendimento pode ser visto quando um ser humano tem que adicionar ou retirar algum significado para uma determinada busca sem que esse esteja diretamente ligado com o termo principal e o computador compreende.
Porém, o Processamento de Linguagem Natural é considerado um problema difícil da área da computação. Nós humanos escrevemos há milhares de anos e, por causa disso, temos uma enorme facilidade de entender as nuances que as nossas linguagens têm. Além disso, nós somos seres emocionais, o que, com certeza, influencia a nossa escrita e a nossa leitura. Esses dois fatores fazem com que o trabalho da máquina seja ainda mais difícil, uma vez que o computador não é capaz de entender as entrelinhas do texto.
O principal trabalho dos estudiosos dessa área é encontrar algoritmos que consigam transformar a nossa linguagem em lógica computacional. Durante a história do Processamento de Linguagem Natural, vários desses algoritmos foram desenvolvidos e tidos como avanços tecnológicos. Serão citados aqui alguns dos principais. O primeiro algoritmo que teve destaque na história foi o Georgetown–IBM experiment, o qual, desenvolvido pela Georgetown University em parceria com a IBM em 1954, conseguiu traduzir mais de sessenta sentenças de russo para inglês. Embora as escritas fossem inseridas em formato de cartões, foi um grande avanço para a humanidade e foi possível mostrar que era possível fazer um tradutor automático naquela época.
Outro programa que revolucionou o mundo através do Processamento de Linguagem Natural foi o/a ELIZA, desenvolvido entre 1964 e 1966 por Joseph Weizenbaum e é tido como o primeiro chatbot existente. O script tinha como objetivo simular um psiquiatra e reagia ao que era digitado com perguntas e respostas parciais que faziam parecer que a pessoa estava conversando com um especialista.
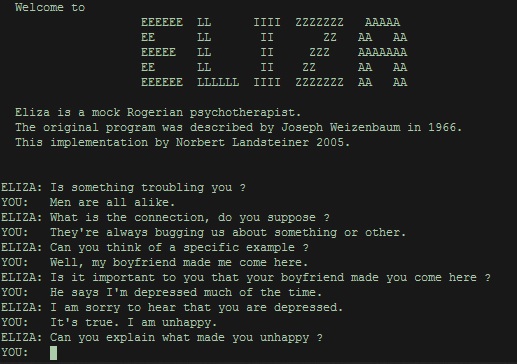
Fonte: le-grenier-informatique.fr
{kind=link}
O grande avanço em PLN veio na década de 80, graças a avanços tanto em hardware (Lei de Moore) quanto em software, com o uso de algoritmos de ML. Agora as regras não precisavam mais ser escritas pelos programadores, elas eram aprendidas de uma base de dados. Esse avanço impacta na performance pois além de remover os vieses humanos que entravam nas regras manuais, também permitiu o processamento de grandes volumes de dados em pouco tempo.
O próximo acontecimento notável foi em fevereiro de 2011. O IBM Watson derrotou os dois campeões de maior sucesso do programa americano de perguntas e respostas, Jeopardy. O sistema da IBM recebia as perguntas por texto, identificava as palavras chaves e a estrutura gramatical e procurava em sua base de conhecimento a resposta que mais faria sentido, e nesse processo todo, de acordo com a IBM, “Mais de 100 técnicas diferentes são utilizadas para analisar a linguagem natural, identificar origem, localizar e gerar hipóteses, localizar e marcar evidências e juntar e rankear hipóteses”. Na época, um simples sistema de perguntas e respostas, hoje já possui diversas funcionalidades como reconhecimento e análise de vídeos e imagem, interação por voz, leitura de grandes volumes de textos e criação de assistentes virtuais.
Um termo muito usado na computação para identificar os avanços mais atuais na computação é o “State of the art”. Se um sistema recebe esse título, significa que ele é o melhor no que foi feito para fazer. Temos muitos sistemas incrivelmente avançados em PLN, como uma Rede Neural do MIT que consegue ler um artigo científico inteiro e gerar um resumo coerente e o sistema da Google de interpretação de texto, que consegue notas mais altas nos testes de Stanford de interpretação que os próprios professores de língua inglesa. Mesmo com feitos tão incríveis como estes, o “State of the Art” mais recente foi dado ao sistema da instituição sem fins lucrativos, a Open AI.
O GPT-2, recentemente desenvolvido pela OpenAI, é um multitask learner, ou seja, não é treinado para uma tarefa específica, como traduzir um texto ou responder perguntas, ele é treinado para diversas tarefas ao mesmo tempo simplesmente lendo e analisando textos brutos. Esse sistema foi alimentado com 40GB de texto da internet e conseguiu bater diversos benchmarks de PLN. O mais fascinante desse modelo é a capacidade de gerar redações de mais de 6 parágrafos sobre um assunto qualquer com quase nenhum erro gramatical. Com a entrada “PLN Timeline”, por exemplo, ele poderia muito bem ter escrito essa matéria que você está lendo.
Processamento de Linguagem Natural é uma das áreas que mais cresce na computação. Hoje, em muitos momentos do dia, já interagimos com bots e logo mais nem iremos perceber que estamos fazendo isso. Se você, leitor do Coruja Informa, tem interesse em estudar estudar PLN, recomendamos que você comece aprendendo Python e depois entrando de cabeça em cursos na internet, como esse gratuito no Udemy. Mais ainda, se você é aluno de SI e está querendo realizar uma IC, TCC, etc. nessa área, dê uma olhada nas pesquisas dos professores Norton Trevisan Roman e Ivandré Paraboni. Nós do PET-SI agradecemos a leitura e até semana que vem! 😉
REFERÊNCIAS:
YSE, D. Your Guide to Natural Language Processing (NLP). Disponível em:
RODRIGUES, J. O que é Processamento de Linguagem Natural?. Disponível em:
KOCHMAR, E. Introduction to Natural Language Processing. Disponível em:
WIKIPÉDIA. History of natural language processing. Disponível em:
WIKIPÉDIA. Georgetown-IBM experiment. Disponível em:
WIKIPÉDIA. ELIZA. Disponível em:
WIKIPÉDIA. Moore’s law. Disponível em:
WIKIPÉDIA. Jeopardy!. Disponível em:
CHANDLER, D. A neural network can read scientific papers and render a plain-English summary. Massachusetts, EUA. Disponível em:
GOOGLE. BERT. Disponível em:
WIKIPÉDIA. OpenAI. Disponível em:
RADFORD, A. et al. Language Models are Unsupervised Multitask Learners. 2019.